データハブとは?システムを作り替えずにデータ統合を実現する方法

近年、企業におけるデータ活用の重要性はますます高まっています。一方で、「システムごとにデータが分断されている」「データの整合性が取れない」といった課題を抱えているケースも少なくありません。
こうした課題を解決する手段として注目されているのが「データハブ」です。
本記事では、データハブの基本的な考え方から、なぜ今必要とされているのか、そしてシステムを大きく作り替えることなくデータ統合を実現する方法についてわかりやすく解説します。
【目次】

Boomiはどのようなことができるのかを1冊にまとめました。
複雑化したシステム環境をつなぎ、連携基盤をクラウドで実現します。
データハブとは?
データハブとは、企業内に分散して存在するさまざまなデータを一元的に集約・管理し、必要に応じて各システムへ連携するための仕組みです。
従来のようにシステム同士を個別につなぎ込むのではなく、データの受け渡しをハブとして集約することで、連携構造をシンプルに保ちながらデータの整合性を確保できる点が特徴です。
また、既存システムをそのまま活かしながら段階的にデータ統合を進められるため、大規模なシステム刷新を伴わずにデータ活用の基盤を整備できるアプローチとして注目されています。
企業にはなぜデータハブが必要なのか
企業のIT環境は年々複雑化しており、複数の業務システムやクラウドサービスを併用することが一般的になっています。
その一方で、データが分散したまま管理されていることで、活用の前提となる整備が追いついていないケースも少なくありません。こうした状況の中で、データを“統合して活用する”ための基盤として、データハブの必要性が高まっています。
システムごとに分断されたデータの課題
多くの企業では、基幹システム、CRM、SFA、各種SaaSなど、用途ごとに異なるシステムが導入されています。
その結果、データはそれぞれのシステム内に閉じた状態となり、横断的な参照や活用が難しくなりがちです。このような分断状態では、必要なデータを都度取得・加工する必要があり、データ活用のスピードや柔軟性が大きく制限されます。
データの不整合がビジネス判断を遅らせる
システム間でデータが適切に連携されていない場合、同じ顧客や取引に関する情報であっても内容に差異が生じることがあります。こうした不整合がある状態では、どのデータを基に意思決定すべきか判断が難しくなります。
結果として、レポート作成や確認作業に時間を要し、意思決定のスピード低下や機会損失につながるリスクも高まります。
データ活用・AI活用を支える基盤整備の重要性
近年は、BIツールによる可視化やAI活用など、データを前提とした取り組みが広がっています。
しかし、元となるデータが分断されて整備されていない状態では、こうした取り組みの効果は十分に発揮されません。データを集約・整備し、一貫性のある形で活用できる状態をつくることが、これからの企業にとって重要な基盤となります。
データハブの活用とシステム間連携の違い
データ統合を進める際、多くの企業ではシステム同士を個別につなぐ「ポイントツーポイント(直接連携)」の方式が採用されています。しかし、システムやSaaSの導入が進むほどに連携は増え続け、その構造が複雑化していくことで、保守や運用の負荷が大きくなるケースも少なくありません。
こうした課題に対して、データ連携をハブに集約するデータハブのアプローチが注目されています。
| システム間の直接連携(ポイントツーポイント) | データハブ | |
|---|---|---|
| 連携方法 | システムごとに個別接続 | ハブを中心に集約 |
| 拡張性 | 接続が増えるほど複雑化 | 比接続先が増えても構造はシンプル |
| 保守性 | 変更時に複数箇所の修正が必要 | ハブ側で一元管理 |
| データ整合性 | システムごとに差異が発生しやすい | 一貫したデータを配信可能 |
| 開発コスト | 連携ごとに個別開発が必要 | 共通化により効率化 |
| 可視性 | 全体像を把握しにくい | データフローを把握しやすい |
直接連携は、初期導入のハードルが低くスピーディに構築できる一方で、システムが増えるにつれて構造が複雑になり、結果的に運用負荷や改修コストが増大しやすいという特徴があります。
一方、データハブは連携を一箇所に集約することで全体構造をシンプルに保ち、変更や拡張にも柔軟に対応できる点が強みです。システム数が増えるほどその効果が発揮されるため、中長期的なデータ活用を見据えたアプローチとして有効といえるでしょう。
ポイントツーポイント(P2P型)連携の限界
システム間の直接連携(ポイントツーポイント)は、個別の要件に応じて迅速に構築できる点が特徴ですが、連携対象の増加に伴い構造が複雑化しやすいという課題があります。システムごとに個別の接続を持つ構成では、新たなシステムの追加や既存システムの変更にあわせて複数の連携処理を修正する必要があり、影響範囲の把握が難しくなります。
また、同様のデータを複数経路で処理する状況が生まれやすく、結果としてデータの不整合や重複が発生するリスクも高まります。初期段階ではシンプルに見える構成であっても、システムの増加とともに運用負荷や保守コストが増大しやすく、中長期的な視点では課題となるケースが少なくありません。
データハブによる統合アプローチ
こうした課題に対して、データハブはシステムを維持したままデータの流れを整理・統合するというアプローチを取ります。各システム間で個別に連携を行うのではなく、データの受け渡しをハブに集約することで、連携構造をシンプルに保ちながら統合を実現できる点が特徴です。
この仕組みによって、既存資産を活かしながら段階的に統合を進めることが可能となり、全体刷新に比べて柔軟性の高い対応が可能になります。
データハブを採用するメリット
データハブを採用することで、システム間連携の複雑化を抑えながら、データ統合を継続的に進めることが可能になります。まず、連携構造がシンプルになることで、保守や更新時の影響範囲を限定でき、運用負荷の低減につながります。
また、データ連携の構造をハブに集約できることで、各システムに一貫したデータを配信でき、整合性の維持できるのも大きな利点です。さらに、接続先が増えても基本的な構造は変わらないため、拡張性にも優れており、将来的なシステム追加やデータ活用の高度化にも柔軟に対応できます。
データハブで実現できること
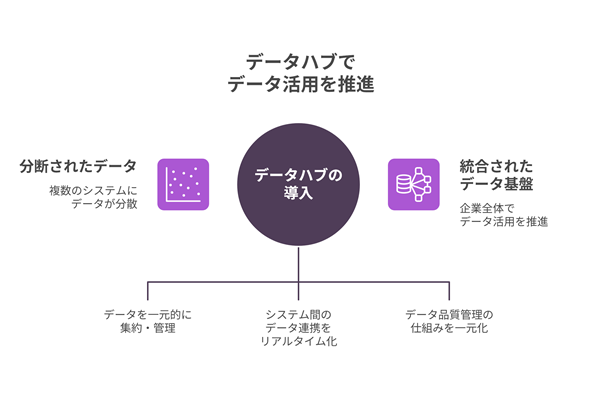
データハブを活用することで、分断されていたデータをつなぐだけでなく、企業全体でのデータ活用を前提とした基盤を構築できます。ここでは、代表的な活用内容を整理します。
マスターデータの統合・一元管理
顧客情報や取引先情報、製品情報といったマスターデータは、多くの企業で複数のシステムに分散して管理されています。その結果、同じ項目であっても内容に差異が生じたり、更新のたびに各システムへ反映する手間が発生したりと、運用負荷が高まりがちです。
データハブを活用することで、こうしたマスターデータを一元的に集約・管理できるようになります。データの“正”となる情報を明確にし、各システムへはハブを通じて一貫したデータを連携することで、整合性の取れた状態を維持しやすくなります。
リアルタイムなデータ連携の実現
従来のデータ連携では、定期的なバッチ処理によってデータを更新するケースが一般的でした。しかしどうしてもタイムラグが発生し、最新の情報をもとにした意思決定が難しくなる場面があります。
データハブを用いるとシステム間のデータ連携をリアルタイム、またはそれに限りなく近い形で実現できます。これにより、各部門が常に最新のデータにアクセスできるようになり、状況に応じた迅速な判断や対応が可能になります。
データ品質の維持とガバナンス強化
データが分散して管理されている環境では、重複データや表記ゆれ、更新漏れといった問題が発生しやすくなります。こうした状態が続くと、データの信頼性が低下し、分析やレポーティングの精度にも影響を与えます。
データハブを活用することで、データの登録・更新ルールや品質管理の仕組みを一元的に設けることができるため、データ品質の維持とガバナンス強化につながります。結果として、安心して活用できるデータ基盤を構築しやすくなる点も大きな特徴です。
データハブ導入を成功させるポイント
データハブは有効なデータ統合のアプローチである一方で、設計や運用の進め方によっては期待した効果を十分に発揮できないケースもあります。そのため、導入にあたっては技術面だけでなく、データの持ち方や運用体制まで含めて全体設計を行うことが重要です。
ここでは、データハブ導入時に押さえておきたい主なポイントを整理します。
適切なデータモデル設計
データハブの中核となるのは、どのようなデータ構造で情報を管理するかという“データモデル設計”です。
特に、顧客や取引先といったマスターデータをどのように定義し、どこを“正”とするのかを明確にすることが重要になります。この設計が曖昧なまま進めてしまうと、統合後もデータの不整合が残ったり、運用の中で再び重複や齟齬が発生したりするリスクがあります。
将来的な拡張や他システムとの連携も見据え、一貫性のあるデータ構造を設計することが求められます。
既存システムとの連携設計
データハブは既存システムを活かす前提のアプローチであるため、それぞれのシステムとどのように連携するかの設計が欠かせません。リアルタイム連携を行うのか、一定間隔でのバッチ連携とするのかといった技術的な選択に加え、どのタイミングでデータを同期するか、どのシステムを起点とするかといった設計も重要になります。
連携設計が不十分な場合、データ反映の遅延や整合性のズレが発生し、結果として現場での利用に支障をきたす可能性があります。業務要件と技術要件の双方を踏まえた設計がポイントとなります。
運用体制とデータガバナンスの整備
データハブは導入して終わりではなく、継続的に運用していくことで価値を発揮します。そのため、誰がどのデータを管理するのか、どのようなルールで更新・利用するのかといった運用体制とガバナンスの整備が不可欠です。
例えば、データの更新フローや承認ルール、品質チェックの方法などをあらかじめ定義しておくことで、データの信頼性を維持しやすくなります。
こうした体制が整っていない場合、時間の経過とともにデータ品質が低下し、再び活用が難しくなるケースも少なくありません。
Boomiで実現するデータハブ
データハブの考え方を実際の業務で機能させるためには、データの統合・管理・連携を一貫して実行できる仕組みが必要になります。こうした要件に対応できるソリューションとして注目されているのが、Boomiというデータ統合プラットフォームです。
Boomi DataHubの概要
Boomi DataHubは、企業内に分散したマスターデータを統合・管理し、信頼できるデータとして全体に提供するためのデータハブ基盤です。各システムに存在するデータを集約するだけでなく、重複排除や標準化を通じて“正となるデータ(ゴールデンレコード)”を生成し、常に整合性の取れた状態で各システムへ連携できる点が特徴です。
また、ハブ&スポーク型の構造により、個別のシステム間連携を最小化しつつ、柔軟かつ拡張性のあるデータ統合基盤を構築できます。
Boomi DataHubで実現する高度なデータ活用
Boomi DataHubの特徴は、単なるデータ統合にとどまらず、AIやAPI活用を前提とした“信頼できるデータ基盤”を実現できる点にあります。
例えば、統合されたデータはそのままAPIとして公開・連携できるため、各システムやサービスから一貫したデータにアクセスできる環境を構築できます。これにより、API単位で分散しがちなデータ管理を統制しやすくなり、企業全体でのデータ活用を加速できます。
さらに、データの来歴や変更履歴を追跡可能な形で管理することで、ガバナンスを担保したデータ活用が可能となり、分析や意思決定の信頼性を高めます。近年重要性が増しているAI活用の観点でも、データハブとして整備された一貫性のあるデータは重要な役割を果たします。
Boomi DataHubでは、信頼性の担保されたデータをAIエージェントに連携することで、文脈に基づいた判断を可能にし、不正確な出力(ハルシネーション)の抑制にも寄与します。このように、単なるデータ連携にとどまらず、「統合・管理・活用」までを一貫して支える点が、Boomi DataHubの大きな強みといえます。
“作り替える”ではなく“つなぐ”という選択
データ活用の重要性が高まり、企業にはスピードと柔軟性が求められています。そうした中で注目されているのが、「作り替える」のではなく「つなぐ」というアプローチです。
データハブを活用することで、既存システムを活かしながら段階的にデータ統合を進めることができ、大規模なリプレイスを伴わずにデータ活用基盤を整備できます。また、統合されたデータをもとに、分析やAI活用といった次のステップへ柔軟に展開できる点も大きなメリットです。
複雑化するIT環境においては、すべてを刷新するのではなく、適切につなぎ、活かすという視点が重要です。データハブは、現実的かつ有効な選択肢の一つになりえます。
まずは、自社のデータ活用における課題を整理し、どのような形でデータ統合を実現すべきかを検討してみてはいかがでしょうか。
Boomiはどのようなことができるのかを1冊にまとめました。
複雑化したシステム環境をつなぎ、連携基盤をクラウドで実現します。