データ統合で分散データを活用する方法とは?基礎から手順・Boomiによる実現まで解説

企業内のデータは、SaaSや基幹システム、オンプレミスなど複数環境に分散し、活用しづらい状態になりがちです。こうした課題を解消する鍵が「データ統合」です。
データ統合は、分散データを一元的に扱えるようにすることで業務効率化、データ品質の向上、迅速な意思決定につながります。また、生成AIや分析基盤を効果的に活用するためにも、正確で統一されたデータ構造が欠かせません。
本記事では、データ統合の基礎からメリット、進め方、BoomiによるETL活用までをわかりやすく整理します。
【目次】
データ統合とは?企業に求められる背景
分散するSaaSや基幹システム、オンプレミス環境とクラウドが混在する現在、データの全体像を把握しづらい状況が生まれています。データ統合の基本を整理し、似て非なる「データ連携」との違いも解説します。
データ統合の定義と「データ連携」との違い
データ統合は、分散データを一元的に整備・管理し、共通の定義で再利用できる状態をつくる取り組みです。対してデータ連携は、システム間でデータの受け渡しを自動化する仕組みを指します。すなわち連携は「運搬」、統合は「運搬+整備・定義・品質管理」までを含む概念です。
データ統合の重要性と目的
統合の目的は、①サイロ化の解消、②データ品質の向上、③意思決定と自動化の高速化、の三点に集約されます。部門ごとの定義差や重複管理を放置すると、分析結果の信頼性が揺らぎ、AI活用も進みません。
データ統合は、組織全体で同じ言葉で同じ数字を語れる状態をつくり、業務と経営をつなぐ“共通言語”を提供します。
データ統合の効果とメリット
データ統合は単にデータを集める作業ではありません。品質・定義・所在の管理を通じて再利用性を高め、現場の判断や自動化に直結する“使えるデータ”へ引き上げる営みです。本章では、実務で効く効果を整理します。
分散データの一元管理と品質向上
データ統合により、どこのデータを正とするか定め、重複・欠損・定義の揺れを抑制できます。特に「どのデータが、どこに、どの意味で存在するか」を可視化する仕組みは重要です。
リアルタイム活用と意思決定スピードの向上
最新データをタイムリーに集約し、ダッシュボードやアラートへ供給することで、現場の判断は俊敏になります。販売・在庫・顧客接点の指標が同じ定義で更新されれば、会議の“数字合わせ”が減り、議論は打ち手に集中します。結果として、機会損失の削減と業務の平準化が進みます。
部門横断のデータ活用とサイロ解消
部署横断で共通指標と参照元がそろうと、データの二次利用・再利用が進みます。マーケ・営業・CS・経理などが同じ顧客ID・製品IDを参照すれば、施策の効果検証もスムーズです。
データ統合は、部門最適から全体最適への移行を促し、継続的な改善サイクルを回しやすくします。
データ統合の主要アプローチ(ETL / ELT / データ仮想化)
データ統合を実現する技術アプローチは複数あります。既存資産・データ量・更新頻度・コストなどの条件に応じて、適材適所で組み合わせます。
ETLとは?
ETLは、Extract(抽出)→ Transform(変換)→ Load(格納)の順で処理する方式です。
変換を実行してからDWHなどにロードするため、配下の分析系は軽く保てます。バッチ処理に適し、業務日次・時間単位の更新に強みがあります。前処理で品質をそろえられるため、下流の再利用性が高まります。
ELTとは?
ELTは、Extract→Load→Transformの順で先にデータ基盤へ取り込み、変換は基盤側(SQL/エンジン)で行います。
クラウドDWHの計算資源を活用でき、大容量・高頻度の更新に適します。スキーマの柔軟性が高く、アドホック分析の試行錯誤にも向いています。
データ仮想化とは?
データ仮想化は、物理的に統合せず“論理的に一元化”して見せるアプローチです。レプリカを作らずにビューを組むため、即時性や原本主義を保てます。
一方で、元システムの可用性や性能の影響を受けやすい点は設計配慮が必要です。ETL/ELTとのハイブリッドが現実解となるケースが多いです。
データ統合がうまくいかない理由
データ統合がうまくいかない理由の多くは、ツールよりも設計と運用に起因します。ありがちな落とし穴を先に把握しておくと、再設計や手戻りを減らせます。
システムごとの仕様差による保守負荷
個別最適の連携を積み上げると、接続パターンの爆発が起き、変更対応が遅れます。仕様差を吸収する共通ルールがないまま開発すると、担当者依存が増し、保守コストが逓増します。
まずは共通の命名・型・コード体系を決め、再利用前提で組み立てることが重要です。
ブラックボックス化・変更耐性の低さ
「どのデータが、どこから来て、どこへ使われるか」が見えないと、影響範囲が読めず改修が止まります。系統図・データライネージの整備と、変更管理フローの設置は必須です。属人化を避け、仕様を“資産化”するほど、変更に強くなります。
データの意味・所在・責任の曖昧さ
定義が部門で異なる、責任者が不明、といった状態では品質は上がりません。用語集・メタデータ・責任者(Data Owner/Steward)の明確化と棚卸しサイクルを仕組み化しましょう。データ統合は“運用して育てる”もの、という意識が成功率を高めます。
データ統合の進め方・5ステップ
すべてを一度に変えるのではなく、小さく始めて速く回すことが大切です。以下の5ステップを目安にデータ統合を進めてみてください。
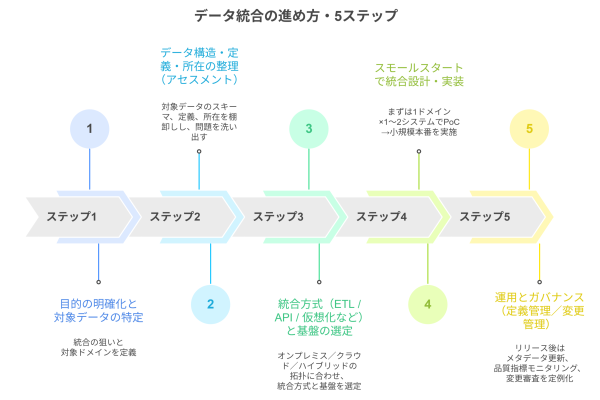
ステップ1:目的の明確化と対象データの特定
狙い(例:レポートの標準化、在庫指標の“正”の確立、AI学習データの整備)を言語化し、先に効かせたいドメイン(顧客・売上・商品など)を限定します。意思決定の現場で“最初に困っている場所”から着手するのが成功の近道です。
ステップ2:データ構造・定義・所在の整理(アセスメント)
対象データのスキーマ、定義、粒度、更新頻度、責任者を棚卸しし、現状の問題(重複・欠損・命名不統一)を洗い出します。ここで共通ID設計と用語定義を決めることで、後続の統合と品質改善がスムーズになります。
ステップ3:統合方式(ETL / API / 仮想化など)と基盤の選定
オンプレミス/クラウド/ハイブリッドの拓扑に合わせ、方式を組み合わせます。レガシーはバッチETL、SaaSはAPI、即時性はイベント駆動、分析はELTなど要件×方式マトリクスで最適解を作ります。将来の拡張を見越し、スケール・ガバナンス・可観測性を評価指標に含めます。
ステップ4:スモールスタートで統合設計・実装
まずは1ドメイン×1〜2システムでPoC→小規模本番を実施。命名規則・バリデーション・エラーハンドリング・監視をテンプレ化し、横展開できる型を作ります。ドキュメントとIaCの最小セットも同時に整備します。
ステップ5:運用とガバナンス(定義管理/変更管理)
リリース後はメタデータ更新・品質指標モニタリング・変更審査を定例化。新規システム追加の標準フロー(接続申請→スキーマ審査→本番投入)を設け、属人化しない運用を回します。
Boomiで実現するデータ統合(ETL/データ管理)
ここでは、実装段の解像度を一段上げ、Boomiの特長をETL/データ管理/アーキテクチャの観点で整理します。ノーコード/ローコードでの開発生産性と、変更に強いガバナンスを両立できる点がコア価値です。
Boomi IntegrationのETL機能
Boomiの強みは豊富なコネクタ群にあることはもちろん、複雑な変換が含まれていてもドラッグ&ドロップのマッピングで対応できることにあります。ローコード/ノーコードで抽出・変換・ロードを短時間で構築可能です。
標準の変換コンポーネント(フィルタ、集計、正規化、検証)により、再利用しやすい処理フローを作成できます。バッチもイベント駆動も一つの運用で扱えるため、段階的な高度化に向きます。
Boomi DataHubによるデータ統合・定義管理
Boomi DataHubは、メタデータ管理とマスタ的統合を担い、技術用語と業務用語を結びつけます。
用語集・責任者・品質指標を一元化し、どのデータをどの定義で使うかを組織横断で共有可能です。統合で整えた“正”のデータを、安心して全社に配布できます。
API連携やイベント駆動を含む柔軟アーキテクチャ
IntegrationとAPI管理を連携し、リアルタイムな連携面を強化できます。
キュー/ストリーム等と併用すれば、即時性と疎結合を両立。監視・ログ・バージョン管理も仕組みに組み込めるため、変更に強い運用を作りやすいのが特長です。
データ統合は“仕組み化”が最重要
データ統合を成功させるためのポイントは下記の3つです。
目的・対象データ・利用部門の明確化:なぜ統合するのか、どのデータを扱うのか、誰が使うのかを整理し、統合の方向性をぶらさないための軸をつくります。
統合ルール・定義・責任の整理(ガバナンス):データの意味や所在、管理者を明確にし、品質と再現性を担保できる運用体制を整えます。
将来の追加と拡張に耐える基盤を選ぶ:オンプレ/クラウドを含むシステム追加や業務変化に柔軟に対応できる仕組みを選び、長く使える統合環境を構築します。
データ統合は、分散したデータを一元的に活用し、業務効率化や意思決定の高度化を実現するための重要な取り組みです。本記事で解説した内容を踏まえ、まずは小さく始めながら、将来の拡張を見据えた基盤づくりを進めることが大切です。