この記事の内容

あなたは毎朝、未処理チケットの山に頭を抱えていませんか?
システムの老朽化により対応が担当者ごとに属人化し、問い合わせ対応の品質にバラつきが生じている…そんな現場の悲鳴が聞こえてきそうです。変革の必要性は痛感していても、何から手を付ければ良いのか戸惑っている方も多いでしょう。実際、「ServiceNow 導入 方法」や「ITIL 導入 方法」と検索しても断片的な情報ばかりで、具体的な道筋が見えにくいのではないでしょうか。属人的な対応から脱却し「インシデント対応の自動化」に踏み切りたいものの、社内の抵抗やスキル不足への不安もあるかもしれません。
本稿では、ITサービス運用グループ責任者であるあなたに寄り添い、ITILベストプラクティスとServiceNowプラットフォームを活用したITSM自動化の実践ステップを解説します。インシデント管理や変更管理など主要プロセスの整備から、自社環境での具体的な設定ポイント、さらに新しい仕組みを現場に定着させるコツまでを網羅しています。
平均復旧時間(MTTR)の短縮やサービス品質向上による顧客満足度(CSAT)の改善が期待でき、35%のMTTR短縮や残業時間30%削減も夢ではありません。ITILとServiceNowによるITSM自動化の全体像をつかみ、明日から使えるヒントを見つけてください。
ステップ1:現状分析と目標設定
ステップ1では、まず現状を客観的に分析し、改善すべき領域と達成目標を明確に定めます。
現状把握なくして適切な解決策は導き出せません。以下のポイントで自社のITサービス運用を見直しましょう。
現状分析:データ収集と課題整理
まずは自社のITサービス運用の現状を客観的に洗い出します。
未処理チケット数や平均対応時間、問い合わせ内容の分類など、定量的なデータを収集して実態を把握しましょう。同時に現場の声にも耳を傾け、日々の運用でどの業務プロセスにボトルネックがあるかを調査します。インシデント管理・問題管理・変更管理などITILの基本プロセスごとに現在の対応方法や課題を整理することで、どの領域を優先的に改善すべきかが見えてきます。
ITILが定義する主なプロセスには以下のようなものがあります。自社の対応状況と照らし合わせながら課題を洗い出してみてください。
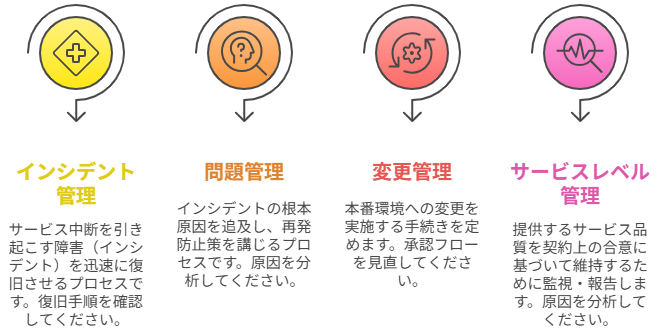
• インシデント管理:サービス中断を引き起こす障害(インシデント)を迅速に復旧させるプロセスです。現在は担当者ごとに対応が異なっていないでしょうか?復旧までの手順が明文化されているか確認しましょう。
• 問題管理:インシデントの根本原因を追及し再発防止策を講じるプロセスです。障害の度に場当たり的な対応になっていないか、原因分析と恒久対策が機能しているか点検します。
• 変更管理:本番環境への変更をリスクを抑えて実施する手続きを定めるプロセスです。変更前後の承認フローやテスト計画が整備されているか、変更履歴が適切に管理されているかを見直しましょう。
• サービスレベル管理:提供するサービス品質を契約上の合意(SLA)通りに維持できるよう監視・報告するプロセスです。現在のサービス稼働率や応答時間は目標に達していますか?SLA違反が発生していれば原因を分析します。
• 構成管理:構成管理データベース(CMDB)を用いてIT資産やシステム構成を管理するプロセスです。インフラ構成情報が散在していないか、CMDBで一元管理できているか確認しましょう。インシデント発生時に影響範囲を正確に把握するための基盤となります。
ITILに沿った目標設定
現状が把握できたら、次にITILに沿った改善目標を設定します。ビジネス戦略とITを整合させる観点から、サービス品質指標となるKPI(例:SLA達成率や平均復旧時間=MTTRなど)の目標値を具体的に定めましょう。目標は可能な限り定量的かつ明確に、いわゆる「SMART」な形で設定します。
例えば:
• 「インシデント一次対応の平均復旧時間(MTTR)を現状より25%短縮する」
• 「重要システムのサービス稼働率を99.9%(現在は99.5%)に向上させる」
といった具合です。これらの目標は、後述するServiceNow導入プロジェクトのROI(投資利益率)を経営層に示す根拠にもなります。ビジネスに与える価値を数値で示すことで、プロジェクトへの社内理解と支持を得やすくなるでしょう。

業務フローの可視化とボトルネック分析
現状分析の一環として、各プロセスの業務フローを可視化することも有効です。例えば、インシデントの発生から解決までの手順をフローチャートに描いてみましょう。どの段階で対応が滞っているのか、手戻りや重複作業が発生していないかが一目で分かります。
属人的な判断に頼っている箇所や、二重入力など非効率な作業が見つかれば、それらは自動化によって削減すべき対象です。このようにボトルネックと改善ポイントを洗い出すことで、ServiceNow導入によって具体的に何を解決すべきかが明確になります。
定量的なビジネスインパクト評価
また、定量データに基づくビジネスインパクトの評価も欠かせません。システム障害が発生した際の1時間あたりの業務損失額や、手作業による対応に費やしている人件コストを算出し、ITSM自動化による削減余地を見積もります。
例えば「MTTRを1時間短縮すれば年間〇〇円の損失を防げる」あるいは「手動対応を自動化することで年間△△時間の工数削減が可能」といった具体的な数字を導き出しましょう。こうしたデータは説得力が高く、経営層へのアピール材料となります。現状の課題がビジネスに及ぼすインパクトを数値で見える化することで、ITSM自動化プロジェクトの優先度と必要性を客観的に示すことができます。
プロジェクト推進体制の構築
最後に、ServiceNow導入に向けたプロジェクト推進体制を準備します。ITSM推進の専任チームや各プロセスのオーナーを任命し、役割と責任を明確に定めましょう。必要に応じてServiceNowやITILに精通した外部パートナーから支援を受けることも検討してください。
新しいツールやプロセスの導入に現場から抵抗が予想される場合は、キックオフ前に説明会やワークショップを開催し、導入の目的とメリットを丁寧に共有します。現場の不安や疑問に事前に答え、意見を取り入れることで、関係者の納得感を高めることが重要です。こうした入念な下準備により、次のステップであるServiceNow導入がスムーズに進み、組織全体での合意形成が図りやすくなります。
ステップ2:ServiceNowのカスタマイズと導入
ステップ2では、優先度の高いプロセスからServiceNow上にITSMプロセスを構築し、自社に合わせた設定を行います。
ITILベースのプロセスをツール上に実装することで、属人的だった対応を標準化・自動化していきます。以下のポイントに沿って導入を進めましょう。
インシデント管理の導入とチケットの一元管理
準備が整ったら、まずは優先度の高いプロセスからServiceNow導入に着手します。多くの企業ではユーザーへの影響が直接的に大きいインシデント管理から開始するケースが一般的です。
ServiceNowにはITILに準拠したインシデント管理、問題管理、変更管理などのモジュールが標準搭載されており、有効化して必要項目を設定するだけで基本的なワークフローを整備できます。現行運用との比較を通じて、導入効果を実感しましょう。
ServiceNow導入前後の変化の例
【チケット管理の一元化】
従来は担当者ごとにメールやスプレッドシートでインシデント対応状況を管理し、情報共有が属人的でした。ServiceNow導入後はすべてのチケットが一元管理され、チーム全員がリアルタイムで状況を把握できます。対応履歴もプラットフォーム上で共有されるため、対応漏れや二重対応が解消されます。
【監視ツールとの連携による即時通知】
既存のサーバ監視ツールや通知システムとServiceNowを連携すれば、障害アラート発生時にインシデントが自動起票され、担当者へ即時通知されます。初動対応の遅れによる障害長期化リスクが低減するでしょう。
【ナレッジ活用による対応スピード向上】
エージェント(IT担当者)はServiceNow上で過去のナレッジベースを検索し、類似事例の解決策を参考にしながら迅速に対応できます。ナレッジとワークフローが統合されたプラットフォームだからこそ、知見の再利用による対応スピード向上が実現します。
【モバイル対応で場所にとらわれない運用】
ServiceNowのモバイルアプリを活用すれば、担当者は移動中でもチケットの更新や承認を行えるため、場所に縛られない柔軟な運用が可能になります。緊急時にオフィス外からでも対応でき、サービス停止時間の短縮につながります。

過度なカスタマイズの回避と標準機能の活用
次に、自社の業務に合わせたServiceNowのカスタマイズを行います。ただし、カスタマイズは必要最小限に留めることが重要です。
フィールドの追加や承認フローの調整など現場の要件に応じた設定変更は可能ですが、標準機能で代替できないか常に検討してください。過度なカスタマイズは将来のバージョンアップ時に障害となるため、ベストプラクティスに沿った形での運用を心がけます。例えば、独自のスクリプトを記述して機能拡張することは可能ですが、複雑なスクリプトはアップグレード時に動作しなくなるリスクがあります。そのため保守しやすい範囲で実装を留め、可能な限り標準機能や公式プラグインで要件を満たすことが望ましいでしょう。
CMDB構築と関係性の管理
技術的な設定面では、構成管理データベース(CMDB)の構築が重要なステップです。
ServiceNowのCMDBにサーバーやソフトウェアなどの資産情報を登録し、それぞれの関係性(依存関係)を紐付けます。例えば「どのサービスがどのサーバーに依存しているか」「このサーバーが障害を起こすとどの業務に影響するか」といった情報をあらかじめ整理・登録しておきます。これによりインシデント発生時に影響範囲を即座に把握でき、問題の原因特定や変更時のリスク評価が格段に容易になります。
また、構成管理が徹底されていれば、変更管理プロセスにおいて承認者が正しい判断を下すための材料ともなります。SN導入時には資産台帳からのデータ移行や、自動発見ツールによる機器情報の取り込みなどを通じて、最新のCMDBを整備することを忘れないでください。
ワークフローの自動化と通知設定
さらに、ServiceNow上でワークフロー自動化の設定も行いましょう。
インシデントから問題管理・変更管理へのエスカレーションを自動化したり、定型的な承認プロセスはビジネスルール機能で自動化できます。チケットの状態変化を関係者に自動通知する通知機能も活用し、対応漏れを防止しましょう。
IDCの分析では、このようにインシデント対応を自動化することで平均復旧時間(MTTR)が最大30%短縮できたとの報告があります【¹】。手動対応のプロセスを自動化することで、人為ミスの削減や対応スピード向上といったITSM自動化の効果がデータで裏付けられているのです。
セルフサービスポータルとチャットボットの活用
ユーザーエクスペリエンス向上の観点では、セルフサービスポータルとチャットボットの活用も導入段階で検討しましょう。
エンドユーザーが自分でよくある質問を検索したり、サービスの問い合わせや依頼を起票できるようにポータルを整備し、ナレッジベースを充実させます。例えばパスワードリセットやVPN申請など定型的な依頼はフォーム化してポータルから受け付けることで、問い合わせ対応にかかる手間を削減できます。
またチャットボットを導入すれば、パスワードリセットの方法案内など簡易な問い合わせには自動応答で処理することも可能です。これによりヘルプデスクの負荷軽減と初期応答時間の短縮が期待できます(ひいてはユーザー満足度向上にも直結します)。
円滑な導入に向けた体制整備とトレーニング
導入プロジェクト進行中は、常にITILプロセスのベストプラクティスに沿って設定が進んでいるかを確認します。プロジェクトチーム内で週次の進捗レビュー会議を開き、課題があれば速やかに対策を講じましょう。
また、システム構築と並行して現場担当者へのトレーニングも開始します。新しいServiceNow上でのチケット登録方法、エスカレーション手順、運用ルール(優先度の定義やエスカレーション条件など)をマニュアル化し、関係者全員に周知徹底します。段階的なリリースも有効な戦略です。まず一部部署でパイロット運用を実施して問題点を洗い出し、そのフィードバックを反映させた上で全社展開すると良いでしょう。
切り替え当日はサポート要員を通常より手厚く配置し、想定外のトラブルにも即座に対応できる体制を整えておきます。新システムへの不安を取り除き、スムーズな定着を図るために、入念なフォローアップが欠かせません。
ステップ3:運用と継続的サービス改善
ステップ3では、導入した仕組みを日々の運用に定着させ、継続的にプロセスを改善していきます。
新システムの効果を最大化するため、運用フェーズでも計測と改善のサイクルを回し続けましょう。
KPIモニタリングと継続的サービス改善
ServiceNow導入後は、新しい仕組みを定着させつつ主要KPIを継続的にモニタリングします。
ServiceNowに用意されたダッシュボードやレポート機能を活用し、インシデント件数・MTTR・SLA遵守率・再発率といった指標を見える化しましょう。週次・月次の定例サービスレビュー会議を開催し、設定した目標値に対する達成度をチームで確認します。特にMTTR(平均復旧時間)やチケット解決までの各工程を可視化することで、どの段階に時間がかかっているかを詳細に分析できます。問題管理プロセスを通じてインシデントの根本原因を究明し、再発防止策を講じるといったサイクル(いわゆる継続的サービス改善 = CSI)を回し続けることが重要です。
小さな改善であっても継続することで、大きな品質向上につながります。
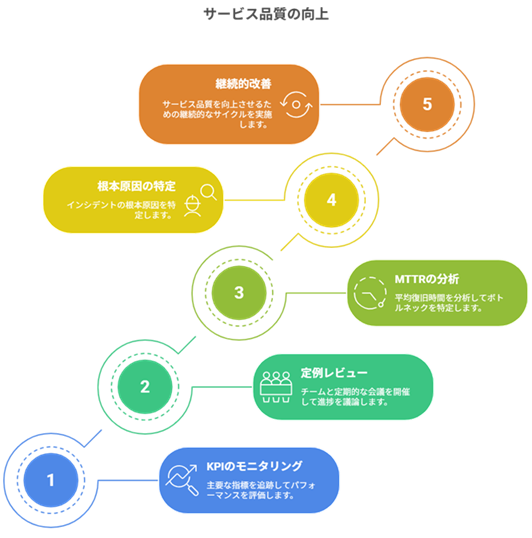
エンドユーザーからのフィードバック収集
また、エンドユーザー(社内外問わずサービス利用者)からのフィードバック収集も積極的に行います。
ServiceNowのアンケート機能や定期ヒアリングを活用し、「ポータルで解決できなかった問い合わせは何か」「サポート対応への満足度はどうか」といった現場の声を集めましょう。得られたフィードバックはナレッジベースの充実やサポートプロセスの改善につなげます。例えば問い合わせが多い分野には新たなQ&A記事を追加し、チャットボットの回答精度を向上させる、といった施策が考えられます。
現場の声を継続的に取り入れることで、システムと運用プロセスをより実情に即した形に育てていくことができます。ユーザー視点で改善を続けることで、結果的にサービス品質と満足度の向上に結びつくでしょう。
変更管理の徹底とCMDBメンテナンス
ガバナンス面では、変更管理プロセスを厳守し無秩序なシステム変更を防止します。ServiceNow上で変更要求のワークフローを定着させれば、全ての変更が記録・承認されるため監査対応も容易になります。変更管理委員会(CAB)の承認プロセスを正式に運用し、リリース前のリスク評価とテストを徹底しましょう。
また、定期的にCMDBを見直し、新しく追加されたIT資産や構成変更を反映させて常に最新の状態を保つことも重要です。CMDBが陳腐化すると、インシデント発生時の影響範囲特定や変更時のリスク分析に支障をきたすため、継続的なメンテナンスを習慣づけます。さらに、インシデント対応訓練や障害シミュレーションを実施し、緊急時でもチームがスムーズに対応できるよう準備しておきましょう。年次で災害復旧(DR)訓練を行う企業もありますが、日頃からシナリオを設定した演習を行うことで、いざという時に慌てず適切に対処できます。
加えて、現場で実際に改善がうまくいった事例や小さな成功でもチームで共有し称賛しましょう。そうした積み重ねがメンバーのモチベーション維持につながり、変革への前向きな姿勢を醸成できます。継続的改善にはチームの協力と主体性が不可欠です。
サービス品質向上とコスト削減の成果
これらの取り組みを地道に続けることで、サービス品質の向上と業務効率化という確かな成果が現れてきます。
実際、ServiceNowを導入した企業からはSLA達成率の大幅な向上や運用コスト削減が報告されています。部門間の連携強化によって社内のコミュニケーションが円滑化し、従業員満足度(ES)が向上するケースもあります。蓄積されたデータに基づき迅速かつ的確な意思決定が可能となり、経営層からの信頼も高まるでしょう。定量効果として、例えば「インシデント対応の生産性が向上し月間○○時間の工数削減」「年間○○円のコスト削減」など具体的な数字で成果を示せれば、IT部門の社内評価も向上します。
成果が見え始めたら、それをチーム全体で共有し更なる改善意欲につなげましょう。
AI Ops活用によるさらなるITSM自動化の展望
ITサービス管理の世界は常に進化しています。ガートナーは「2025年までにサービス部門の80%がAIを活用してオペレーションの生産性とCX(顧客体験)を向上させる」と予測しており【²】、今後はAI Opsや予測分析の導入によるさらなるITSM自動化が期待されます。例えばシステムログや過去のインシデント傾向をAIが解析し、障害の兆候を事前に検知してプロアクティブな対応を行うことも可能になるでしょう。未知の異常パターンを機械学習で検知し、インシデント発生前に対策を講じるといった未来も現実味を帯びています。
ServiceNow自体も既にAI機能や他システムとの高度な連携機能を備えており、新技術の波に柔軟に対応できるプラットフォームです。組織横断で標準化されたプロセスとプラットフォームを確立できれば、担当者が交代しても一定のサービス品質が維持され、オペレーター離職による影響も最小限に抑えられます。最新テクノロジーも積極的に取り入れつつ、ITILの原則に則った継続的改善を続けていくことで、貴社のITサービス管理は日々進化し、やがて競争優位性の源泉となるでしょう。
まとめ
導入や変革に不安を感じるかもしれませんが、まずは現状のITプロセスの分析から始めてみましょう。継続的な改善を積み重ねることで、IT部門の信頼と価値を高め、ひいては組織全体の成長につなげていきましょう。
外部出典
[¹] IDC「ITサービス運用自動化のメリット」(2024年6月)
[²] ガートナー「カスタマーサービスにおけるAI活用の将来予測」(2023年10月)



 資料ダウンロード
資料ダウンロード